colossal-ai:Making large AI models cheaper, faster and more accessible
官网
github
论文 Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
运行环境
Docker运行
- 需要nvidia-container-runtime支持,WSL不支持,没成功构建
- 构建colossalai镜像
|
|
- 可以直接使用colossalai官方提供的镜像
- 基于colossalai镜像添加软件支持
|
|
直接安装
- 仅Linux支持
- 稳定版:
pip install colossalai
- 稳定版:
- PyTorch扩展:
CUDA_EXT=1 pip install colossalai
- PyTorch扩展:
- 最新版:
pip install colossalai-nightly
- 最新版:
梯度累计
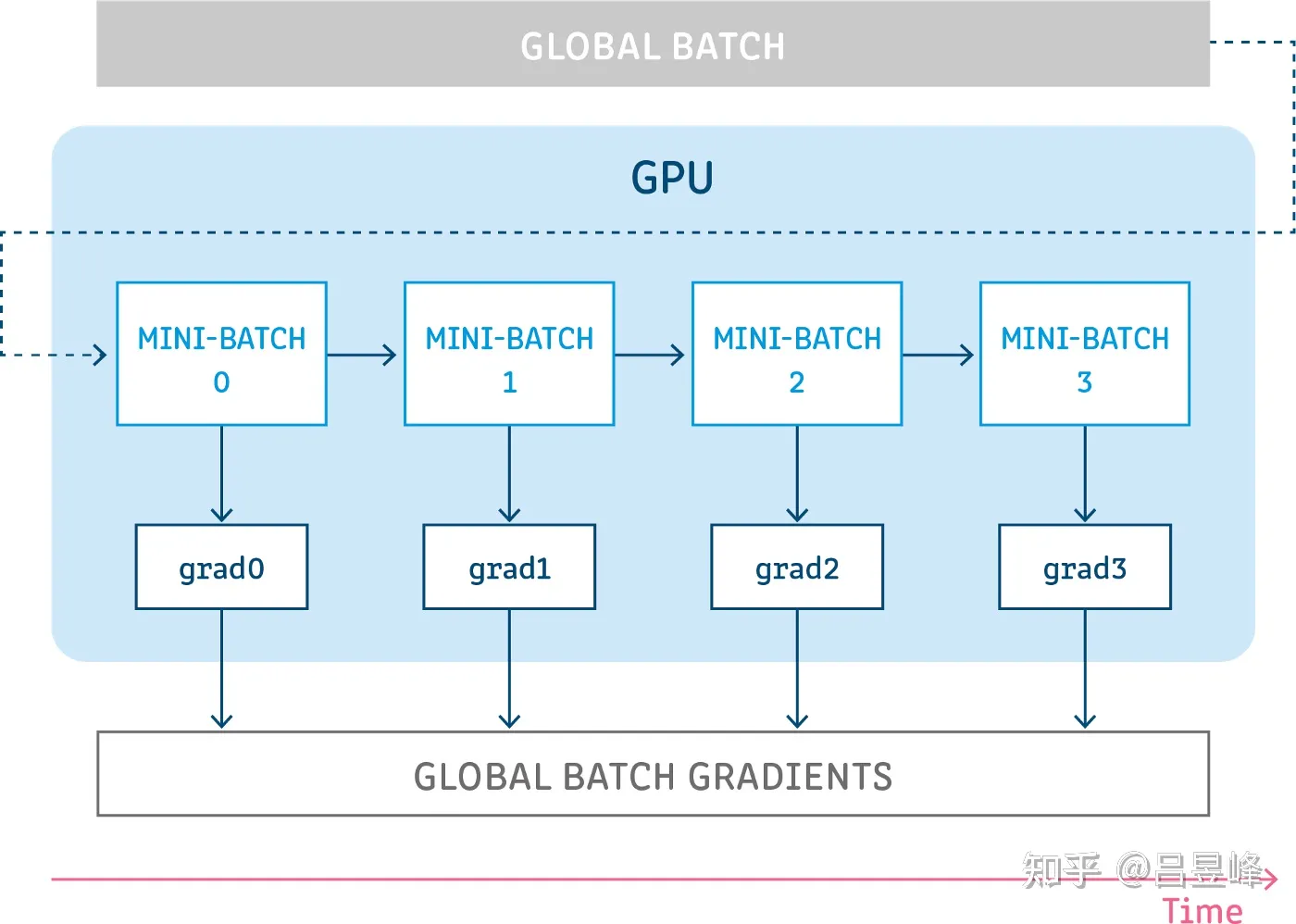
训练模型时由于显存大小有限,batch_size大小会受到限制:可通过多个梯度累积的方法扩大batch_size
- 多个batch执行前向计算,每次前向计算累积反向传播的梯度,但只执行一次梯度更新
- 相当于将batch_size 分成 MICRO_batch_size 和 MACRO_batch_size
- 每MICRO_batch_size个样本做一次前向计算和反向传播,梯度累积在层参数的grad中,不执行梯度更新
- 每MACRO_batch_size个MICRO_batch_size执行一次梯度更新,与此同时,优化器更新/学习率步进/梯度归零
|
|
能否保存多个batch的loss,然后只执行一次反向传播以及梯度更新?不能
以随机梯度下降 Stochastic Gradient Decent 为例,参数 $V$,学习率 $lr$,梯度 $grad$
参数更新公式:$ Vt = V{t-1} - lr grad $ ;
使用梯度累加时:$ V{t} = V{t-1} - lr \sum{i=0}^{N} grad{i} $ 。
|
|
若采用累加多个batch的loss的写法
数学上发生了改变:
$ \partial{loss} / \partial{w} $ 转变成
$ \partial{\sum{t=1}^{N} loss{t}} / \partial{w} $
注意:多个batch的loss累加之后,此时再算梯度的话,由于各网络层的输入x已经发生了改变,算出来的梯度是不准确的
前向传播:x -> f(x) -> y
反向传播:x, y' -> f'(x) -> x'
按正确的pytorch梯度累积代码的逻辑,colossal-ai梯度累积的代码只有一处不同
|
|
然而这种方式训练的网络收敛性有问题
colossal-ai的问题
以上训练过程使用colossalai的GeminiAdamOptimizer
- 基于Gemini内存管理机制实现的Adam优化器
- https://github.com/hpcaitech/ColossalAI/blob/v0.2.8/colossalai/nn/optimizer/gemini_optimizer.py
|
|
其底层封装了ZeroOptimizer和HybridAdam
- HybridAdam实现Adam算法,继承自NVMeOptimizer,支持将数据卸载到NVMe设备上
- ZeroOptimizer实现Zero策略,继承自ColossalaiOptimizer(继承自torch.optim.Optimizer),以实现deepspeed的zero Redundancy内存优化策略
- HybridAdam只实现了step函数,而ZeroOptimizer的step函数做了inf检查之后调用self.optim变量的step函数,而self.optim就是个HybridAdam对象
- GeminiAdamOptimizer调用的函数除了step外,都是在ZeroOptimizer中实现
|
|
- 看ZeroOptimizer的backward函数实现,似乎没什么问题
- 其中self.module是ZeroDDP对象,用于实现模型的并行计算的类
|
|
- 接着看模型的部分,模型被封装成ZeroDDP对象
- backward函数实现了和pytorch的写法一样的loss反向传播
|
|
- 问题出在forward函数上:self.module.zero_grad(set_to_none=True)清空了梯度
- 此处self.module是个torch.nn.Module对象,也就是模型
- 每次forward时都会清空梯度,因此梯度累积不下来,缩放过的loss可能就训练不收敛
|
|
扩展
pytorch中,nn.Module和optim.Optimizer都有zero_grad函数,他们有什么区别?
- nn.Module:https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
- 清空模型所有含参数的层的梯度
|
|
- optim.Optimizer:https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html#torch.optim.Optimizer.zero_grad
- 清空所有传入优化器的层的梯度
|
|
区别在于有时候会冻结模型部分参数进行训练,因此只传入优化器需要训练的部分网络层的参数
colossal的优化器
torch.optim.Optimizer
- Lars:Implements the LARS optimizer
- Lamb:Implements Lamb algorithm
- Adapted from the pytorch-lamb library at https://github.com/cybertronai/pytorch-lamb
- FusedLAMB:Implements LAMB algorithm.
- Fusion of the LAMB update’s elementwise operations
- A multi-tensor apply launch that batches the elementwise updates applied to all the model’s parameters into one or a few kernel launches.
- FusedSGD:Implements stochastic gradient descent (optionally with momentum).
- Nesterov momentum is based on the formula from On the importance of initialization and momentum in deep learning
- NVMeOptimizer:A base class for offloading optimizer states.
- HybridAdam:Implements Adam algorithm.
- Supports parameters updating on both GPU and CPU, the parameters and gradients should on the same device
- an hybrid of CPUAdam and FusedAdam
- CPUAdam:Implements Adam algorithm.
- This version of CPU Adam accelates parameters updating on CPU with SIMD. Support of AVX2 or AVX512 is required.
- FusedAdam:Implements Adam algorithm.
- adapted from fused adam in NVIDIA/apex, commit a109f85
- Fusion of the Adam update’s elementwise operations
- A multi-tensor apply launch that batches the elementwise updates applied to all the model’s parameters into one or a few kernel launches.
- ColossalaiOptimizer
- ZeroOptimizer:A wrapper for optimizer.
ZeroDDPandZeroOptimizerimplement Zero Redundancy Optimizer (ZeRO state-3)
- ZeroOptimizer:A wrapper for optimizer.
- GeminiAdamOptimizer:combine HybridAdam with ZeroOptimizer