1 项目简介
云计算概论课程大作业(2018上半年),即设计云计算相关的一个项目。本文选择在hadoop云计算平台上利用MapReduce框架实现一个重要的机器学习算法,K-近邻算法。k-近邻(k-Nearest Neighbors),即KNN算法,其中k是一个大于0的整数。
Hadoop是一个可以运行MapReduce程序的平台,在避开分布式系统的底层细节下能够开发分布式程序的能力,可以充分发挥分布式集群的运算和存储能力。
KNN分类算法是在一个数据集中找出与给定查询数据点最近的k个数据点,根据这些数据点的标签推断给定数据点的标签。从机器学习的角度,KNN就是在训练集(带标签的数据点集)中分别找出与测试集(标签未知或隐藏的数据点集)中的各个点的k个最近的相邻点。KNN是一种懒学习方法,真正的计算只在分类时才进行。
2 环境搭建
由于要用到Hadoop环境,而Hadoop只能运行在Linux系统上(Windows系统只能通过模拟Linux环境安装Hadoop),而且要模拟集群运算,因此采用虚拟机安装的方案。
实验的详细环境如下:
- 物理机操作系统:Windows10
- 虚拟机软件:VMware Workstation 12 Pro
- 虚拟机系统:ubuntu-14.04.4 64位服务器
模拟的集群架构为1个master主结点,2个slave从结点。
2.1 VMware Workstation Pro的安装和配置
从VMWare官网下载VMware workstation Pro 12.5.7版本的安装包(VMware-workstation-full-12.5.7-5813279.exe),在运行win10操作系统的物理机上安装、激活。
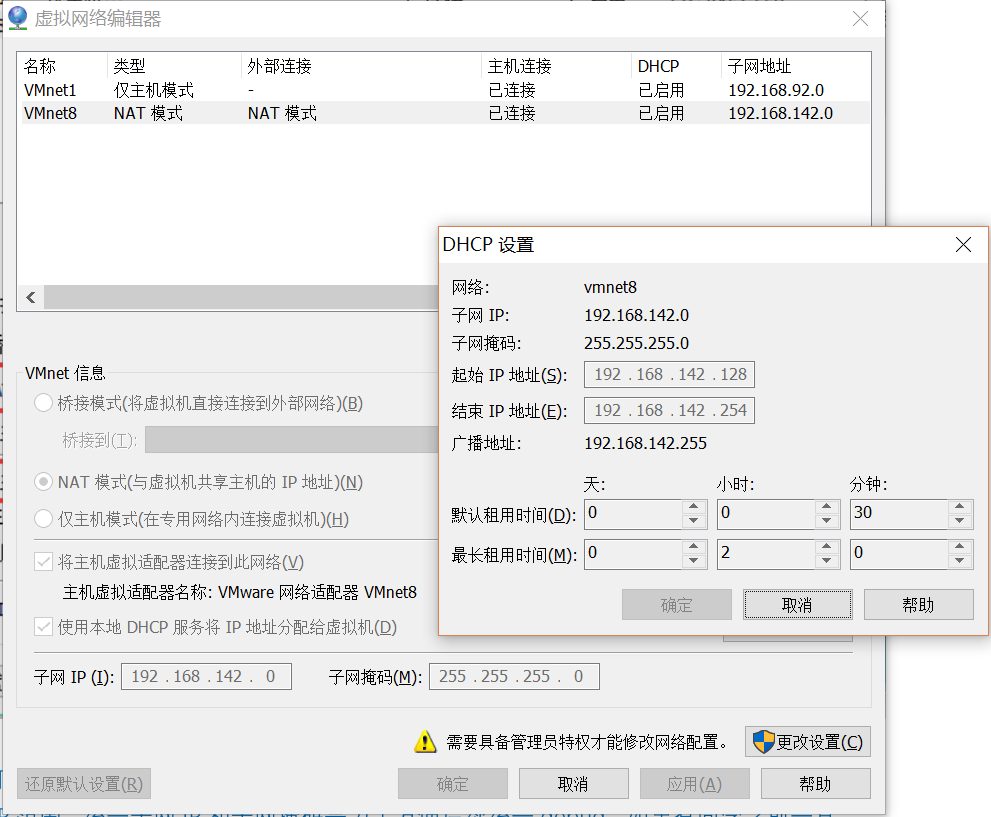
成功安装VMware workstation Pro之后,需要对虚拟网络进行配置。统一子网IP和掩码,设置虚拟机的网段为192.168.142.0,子网掩码为255.255.255.0。
2.2 Ubuntu 14.04的安装
虚拟机软件VMware安装好后,就能安装hadoop的宿主linux系统,Ubuntu14.04 Server。
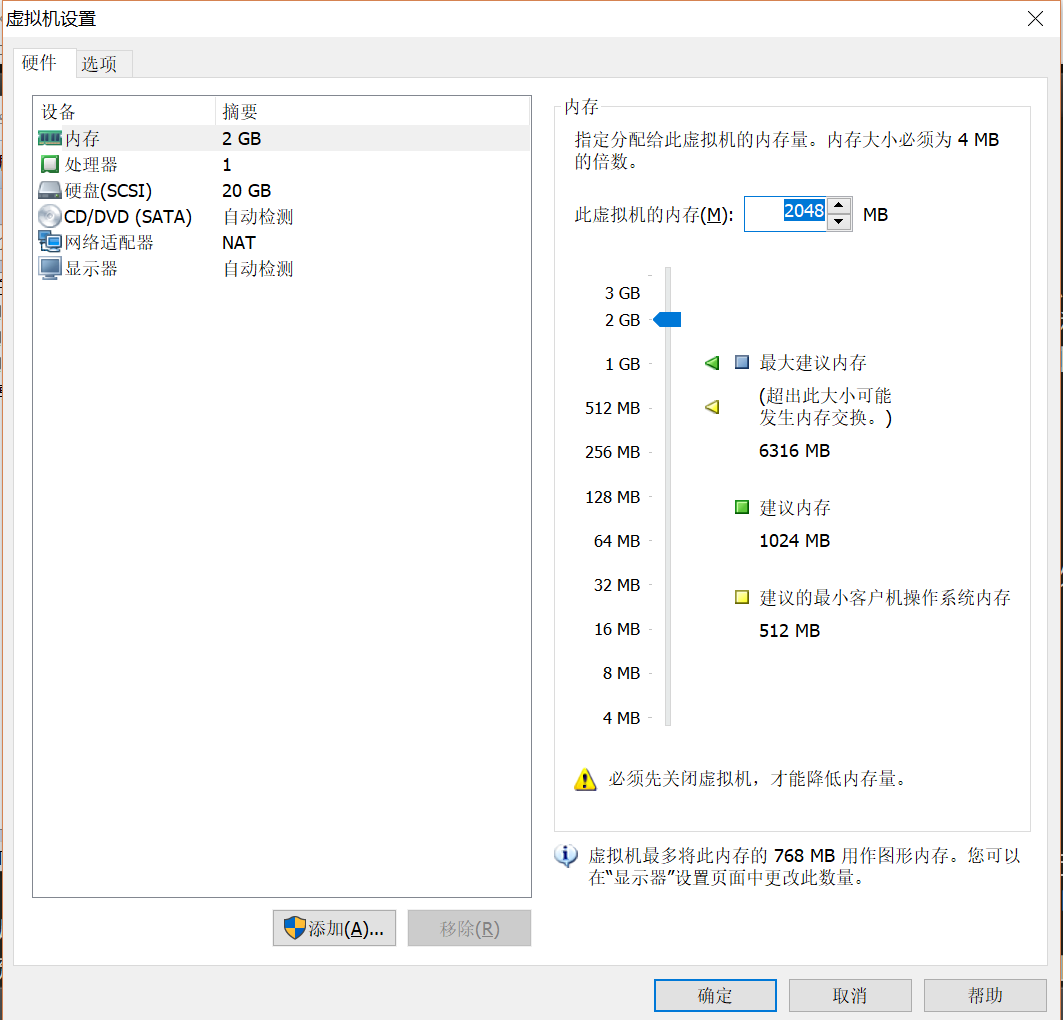
在VMware Workstation Pro的主界面选择创建新虚拟机,Linux Ubuntu64位版客户机系统,虚拟磁盘大小20G,2G内存,移除带默认的USB控制器、声卡、打印机设备驱动,然后就能启动并安装系统。系统要安装三个,虚拟机名称分别为CCmaster、CCslave1和CCslave2,区分master主结点和slave从结点。为了方便实验,将三个虚拟机的用户名和密码全部设定为hadoop。
在系统安装过程中安装软件选择OpenSSH,这个是后面配置ssh连接虚拟机用的。安装过程不可返回,误跳过的话,可在成功安装系统后运行命令sudo apt-get install openssh-server安装ssh server软件。
安装完系统后,将动态分配给各个虚拟机的IP固定下来,修改系统文件/etc/network/interfaces将网卡eth0获取IP方式从dhcp修改为static,绑定IP地址和设定子网掩码、默认网关地址。同时修改DNS配置文件/etc/resolvconf/resolv.conf.d/base将名称nameserver解析为默认网关的地址,即DNS服务定向至默认网关。重启系统即可生效。
为了后续实验的方便,修改/etc/hostnames分别将三台虚拟机主机名设定为master(主结点)、slave1和slave2(从结点),修改/etc/hosts文件将主机名映射到相应IP使得三台虚拟机之间能够互ping通。然后生成各结点的公钥和私钥,达到三台虚拟机之间能够免密码ssh登录。
2.3 Xshell远程连接软件的安装和使用
在VMware workstation Pro中直接操作虚拟机的命令界面有时会比较麻烦,例如查看操作记录不方便,难以往上翻动操作界面,例如鼠标不能使用,给习惯了图形界面系统的使用者带来不便,无法复制粘贴等。因此为了方便实验的操作,可以使用远程连接软件通过ssh连接虚拟机系统,就能更方便地操作虚拟机了。
常用的windows系统下的ssh软件有PuTTY、secureCRT以及Xshell等。实验选择的Xshell是一款商业软件,功能比较丰富,而且有非商用版可以使用。从Xshell官网下载Xshell5安装包安装之后即可使用。
Xshell添加会话即可通过ssh连接到运行有SSH服务器的Linux系统上。
2.4 Java环境和Hadoop环境的安装与配置
Java环境要下载安装jdk,从Java官方网站下载jdk-8u171-linux-x64.tar.gz,使用winscp软件上传到虚拟机,解压到目标文件夹中,在环境变量中加入jdk路径的/lib和/bin目录完成安装。然后在系统配置文件/etc/profile中加入以下命令完成虚拟机开机即可运行Java:
|
|
Hadoop环境依赖于jdk,故三台虚拟机都安装完java后才能进行Hadoop环境的搭建。从hadoop官网下载hadoop-2.9.0.tar.gz,解压到目标文件夹(/usr/local),重命名为hadoop。
然后配置Hadoop各项参数:
/usr/local/hadoop/etc/hadoop/slaves配置文件中加入结点名master、slave1和slave2/usr/local/hadoop/etc/hadoop/core-site.xml配置文件- 设定fs.default.name为
hdfs://master:9000
- 设定fs.default.name为
- 设定hadoop临时文件的目录为
/usr/local/hadoop/tmp
- 设定hadoop临时文件的目录为
/usr/local/hadoop/etc/hadoop/hdfs-site.xml配置文件- 设定dfs.replication为3(3个结点)
- 设定dfs.name目录为
/usr/local/hadoop/hdfs/name
- 设定dfs.name目录为
- 设定dfs.data目录为
/usr/local/hadoop/hdfs/data
- 设定dfs.data目录为
mapred-site.xml配置文件中设定mapreduce.framework.name为yarn- 启用yarn资源管理器,在配置文件
/usr/local/hadoop/etc/hadoop/yarn-site.xml中设定yarn.nodemanager.aux-services为mapreduce_shuffle /usr/local/hadoop/etc/hadoop/hadoop-env.sh环境设定脚本把JAVA_HOME的值改成jdk所在路径
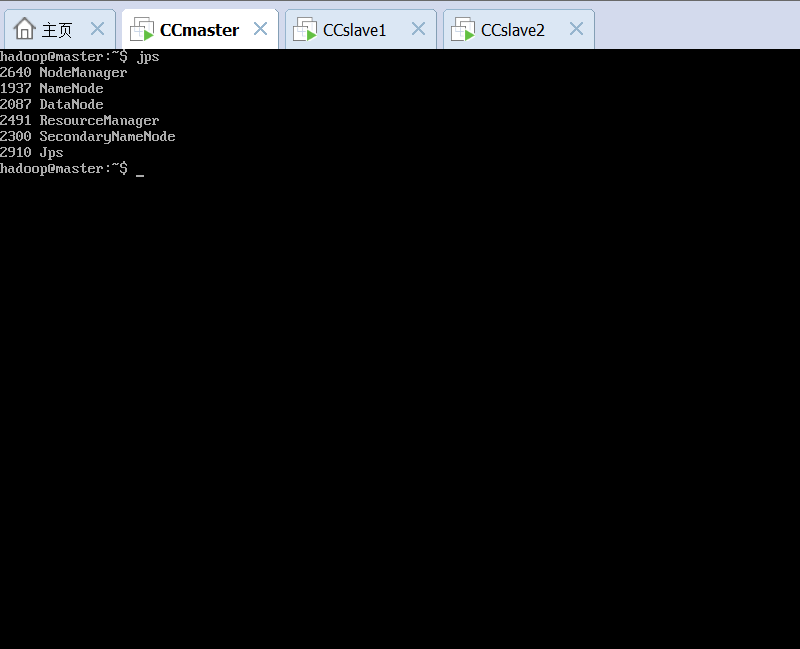
完成Hadoop的配置。然而在格式化namenode并启动hadoop之后,发现50070端口无法访问,8088端口可访问。jps查看各个虚拟机的hadoop启动情况,发现各个结点均正常启动。
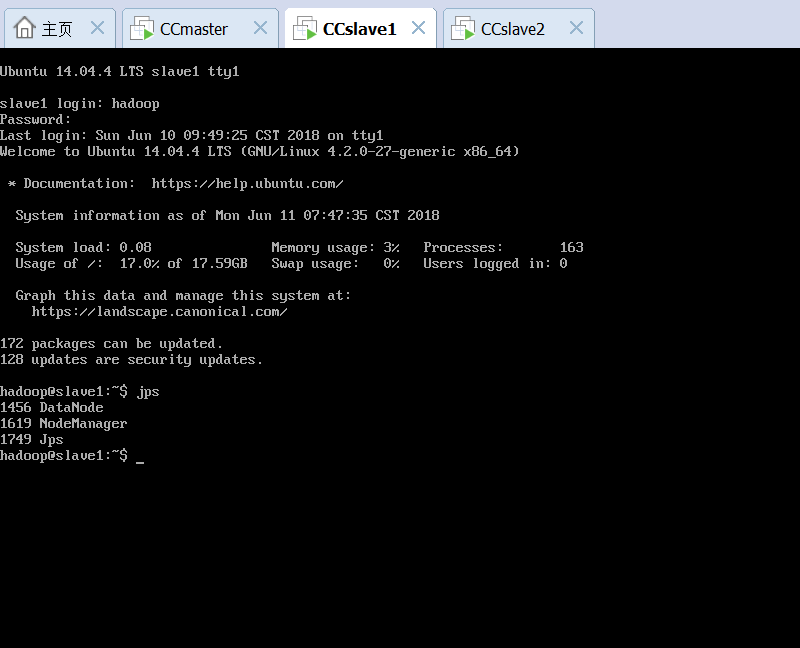
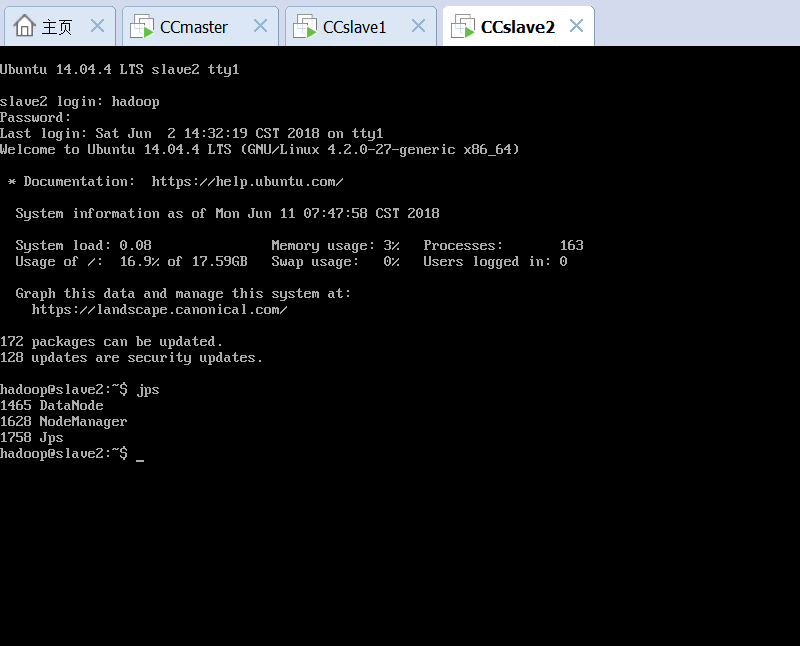
排除了防火墙问题之后,通过查看日志和网络搜索,发现可能是namenode初始化默认端口失败。
清空各个虚拟机hdfs下的name和data文件夹,在master机/usr/local/hadoop/etc/hadoop/hdfs-site.xml文件中加入以下内容:
|
|
然后重新格式化namenode(hdfs namenode -format)才解决问题。成功启动hadoop:
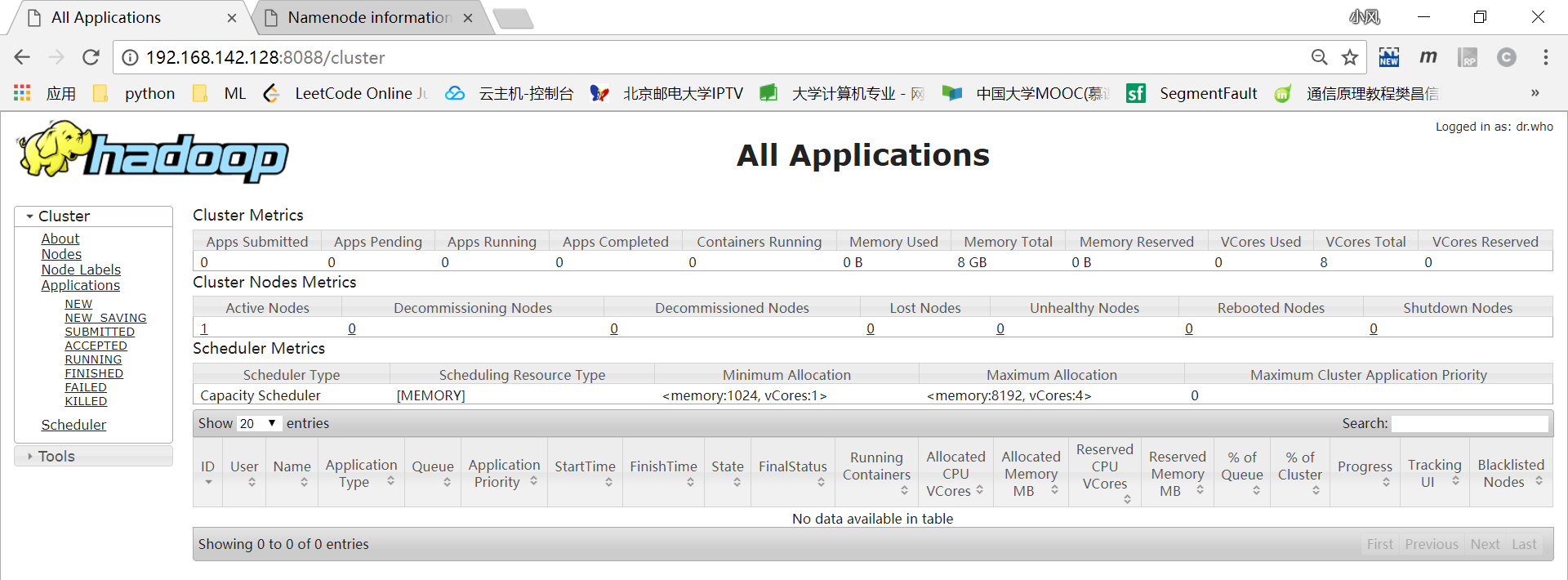
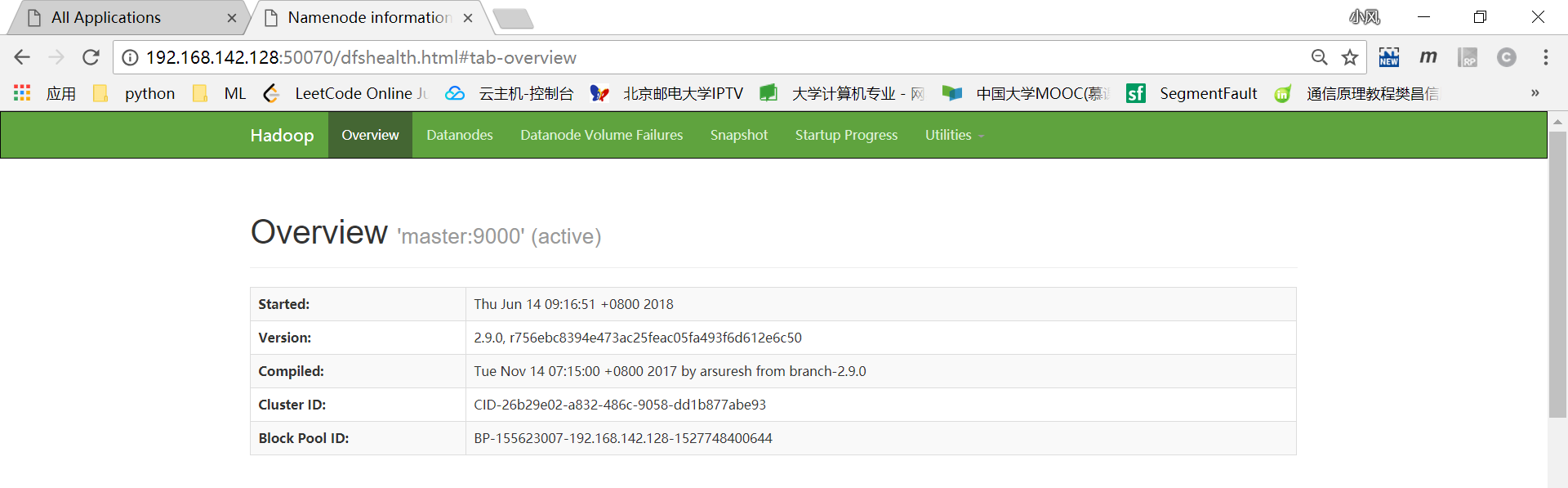
之后用Java编程语言写的mapreduce程序依赖于hadoop环境,因此编写设置环境的脚本setenv.sh,开机后用source setenv.sh命令执行,内容如下:
|
|
至此完成了实验环境的搭建。
3 项目设计
本项目的目的是设计并实现一个基于mapreduce框架的KNN算法。
3.1 程序思路
KNN是一种近邻搜索,根据一个d维对象和其他d维对象的相似度来进行分类的算法,相似度的计算由一个距离函数定义,距离越大相似度越小。经典的欧氏距离是一种度量属性均为实值的对象之间的距离的方法,d维空间中的点$(x_1, x_2, …, x_d)$和$(y_1, y_2, …, y_d)$欧式距离为$Euclidean distance = \sqrt{(x_1 - y_1)^2 + (x_2 - y_2)^2 + … + (x_d - y_d)^2}$。另外还有曼哈顿距离$Manhattan distance = |x_1 - y_1| + |x_2 - y_2| + … + |x_d - y_d|$、 闵可夫斯基距离$Minkowski distance = (\sqrt{|x_1 -y_1|^q + |x_2 - y_2|^q + … + |x_d - y_d|^q})^{\frac{1}{q}}$等距离函数可以采用。对于KNN算法而言,距离函数要根据对象的属性值类型来确定。
KNN算法可以这样描述:设给定带标签的训练集数据点为S,标签未知的测试集数据点为R。对于R中的每一个点P,计算出P与S中每一个点的距离。远近找出k个d维点之后,根据其中相同标签的点最多的标签,将P标记为该标签对应的分类。
算法的主要流程如下:
- 设定k
- 计算输入的点与训练集S中所有点的距离
- 对距离排序,确定最近的k个标签类别
- 计算每个标签类别的数量,根据最多数量的标签确定输入点的类别
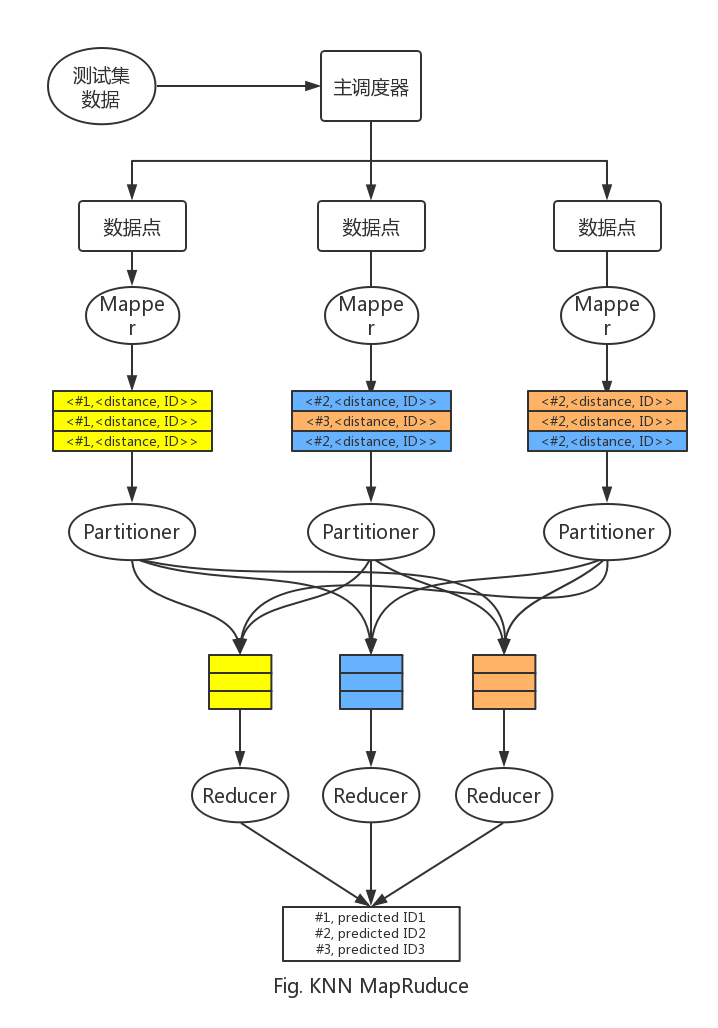
算法要适应MapReduce框架,因而需要定义数据流的处理步骤。
- Mapper类:处理测试集R中的每一行,每一行输入对应一个测试集的点,计算与训练集S中每一个点的距离,得到<距离,标签类别>,输出<输入点序号,<距离,标签类别>>
- Partitioner类:将每个R中的输入点的来自Mapper的输出对<距离,标签类别>,按输入点序号分组传给Reducer
- Reducer类:对每组R中的输入点的<距离,标签类别>,按距离排序,得到距离最小的k个标签类别,计算每个标签类别的数量,从而确定输入点的标签
数据流如图所示:
3.2 程序设计
程序采用Java语言编写。主类名为KNN,将子类定义在主类之中。
在这个程序中遇到一个问题,即训练集数据的共享。由于hadoop各结点之间的内存是不共享的,如果在任务启动之前读取并保存训练集数据在主类的静态变量中,则只有master结点能读取到这些数据,对于其它结点而言该变量是空的。为了能在各结点之间共享数据,查到了四种方法:
- 将需要共享的信息加到输入的key/value对,即在正常的输入之后添加共享数据。这对网络效率和处理效率有比较大的影响。
- 将文件存入HDFS,使用时用HDFS的文件API访问。需要涉及HDFS的文件操作,较为复杂且效率会受到影响。
- 使用JobConf的set方法将共享数据写入配置信息中,需要使用时用JobConf的get方法取出。效率最高,但只适合共享少量数据。
- 将共享数据写入hadoop的DistributedCache中,相关文件会被复制到相关结点的本地临时目录中。只适合于只读数据。
本项目采用了后两种数据共享的方法。在执行程序的命令中需要的两个参数k和d,是Integer型的小数据,故采用第3种方式,将共享数据写入hadoop的jobConf中。训练集数据是只读数据,而且数据量相对较大,采用第4种方式,将数据写入DistributedCache。
首先引入程序要用到的java包,包括java.io包、java.util包以及hadoop的一些包等,然后就可以编写mapreduce程序的主类KNN。
定义距离函数:
对于n维空间中的两个点,$X(X_1, X_2, …, X_n)$,$Y(Y_1, Y_2, …, Yn)$,定义$distance(X, Y) = \sqrt{\sum\limits{i=1}^{n} (X_i - Y_i)^2}$
在程序中的函数名为calculateDistance,有三个参数,分别是rAsString、sAsString和d;rAsString和sAsString是两个点的属性值,分别是含d个用,号分隔开的浮点数类型值的字符串。为了将这两个字符串解析成数组,定义函数splitOnToListOfDouble,将字符串转成List
用字符串类型传递点的属性值是为了使d值可以灵活变动,以及在MapReduce的数据流中数据类型定义比较简单。基于同样目的,使数据类型定义更简单清晰和使后续操作更便利,定义一种数据类型Elem。内部类Elem继承自hadoop的定义数据的基类WritableComparable,包含了两个数据:DoubleWritable类型(double)的distance和Text类型(String)的classificationID;用于表示一对数据,一个距离和这个距离对应的类别标签。同时给Elem类定义必需的构造器、get函数,覆盖基类函数readFields、write以及compareTo(按distance排序再按classificationID排序,后者次序无关紧要)。
KNNMapper继承hadoop的基类Mapper。Mapper的输入类型为LongWritable(long)和Text(String),分别是hadoop为输入生成的key和划分输入得到的value;输出类型为Text(String)和Elem(自定义类型),分别为输入点的序号以及到训练集的点的距离和点的标签。 在KNNMapper类中覆盖map函数,这一函数定义了Mapper的处理逻辑。首先将训练集数据从DistributedCache中读入到静态List
KNNPartitioner继承hadoop的基类Partitioner。Partitioner的输入类型是Text(String)和Elem(自定义类型),将来自Mapper的数据按key分组,使有相同序号的数据传到同一Reducer进行处理。
KNNReducer继承hadoop的基类Reducer。Reducer接收Text和Elem输入,在被覆盖的基类函数reduce中定义得到Text和Text输出的过程。先取出Job configurtaion中近邻数k和数据维度d的值,然后求得输入点的最近的k个邻居,用一个SortedMap
4 实验结果
编写完程序后,在master虚拟机上进行编译和调试。
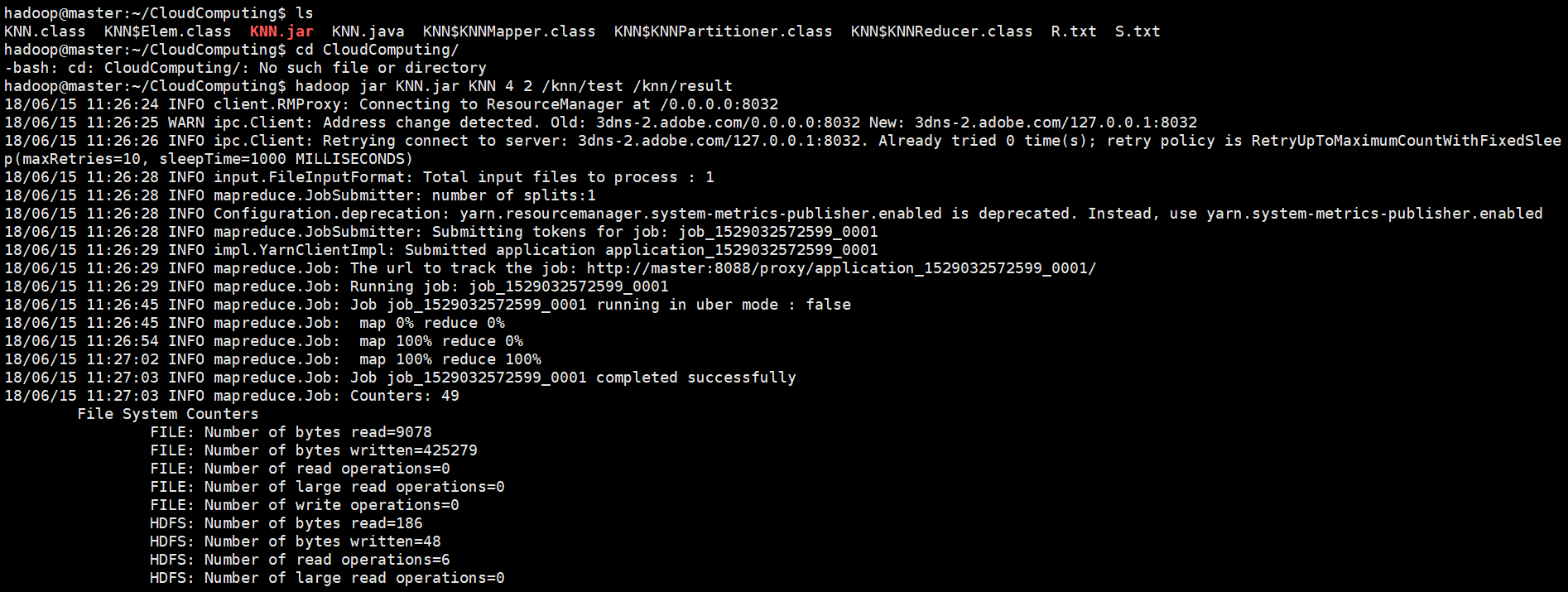
使用命令javac KNN.java编译源程序,然后用命令jar -cvf KNN.jar *.class将class文件打包成jar。调试程序需要三个虚拟机都开机,在master系统上使用命令start-all.sh可启动hadoop。分别在三台虚拟机上使用命令jps检查hadoop启动状态,如果namenode、datanode等任务都正常启动,就能通过hadoop运行MapReduce程序了。
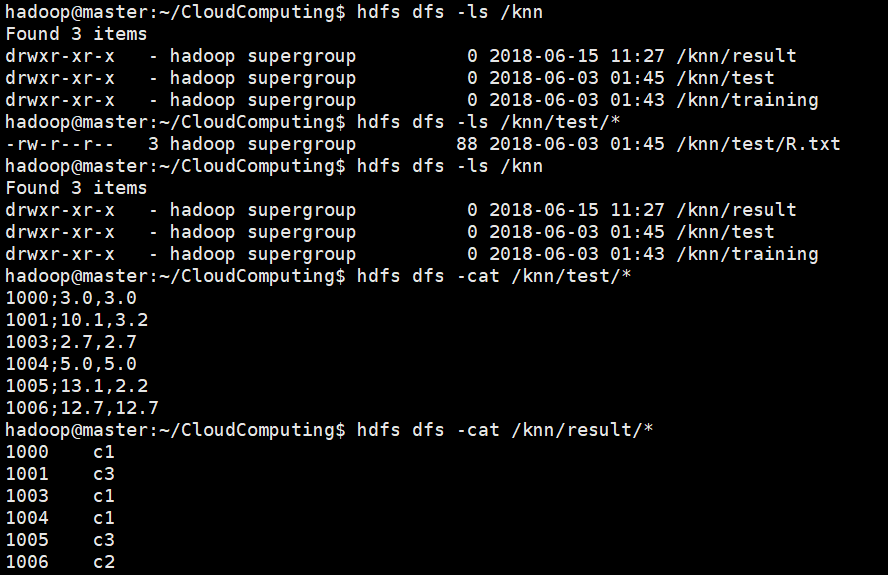
首先在hdfs中创建文件夹,命令为hdfs dfs -mkdir /knn。然后用命令hdfs dfs -mkdir /knn/training在hdfs中创建新文件夹/knn/training,用命令hdfs dfs -put S.txt /knn/training将当前目录下的训练集数据文件S.txt拷贝到hdfs的新文件夹中。使用相同的命令新建文件夹/knn/test将测试集文件R.txt复制到hdfs中该新建的文件夹中。
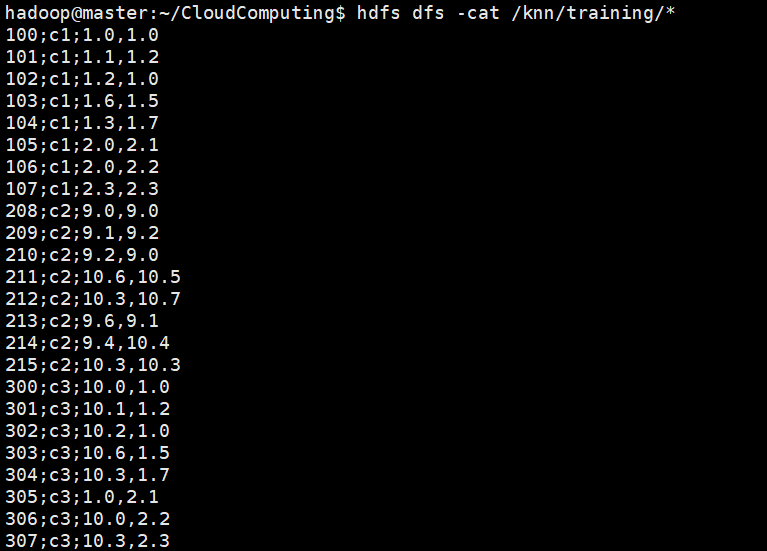
使用hdfs dfs -cat /knn/training/*查看测试程序用的训练集数据,如下:
执行KNN的任务的格式为KNN <k-knn> <d-dimension> <R-input> <output>。
使用命令hadoop jar KNN.jar KNN 4 2 /knn/test /knn/result在hadoop上启动KNN任务,k=4,d=2。执行过程的信息如下所示:
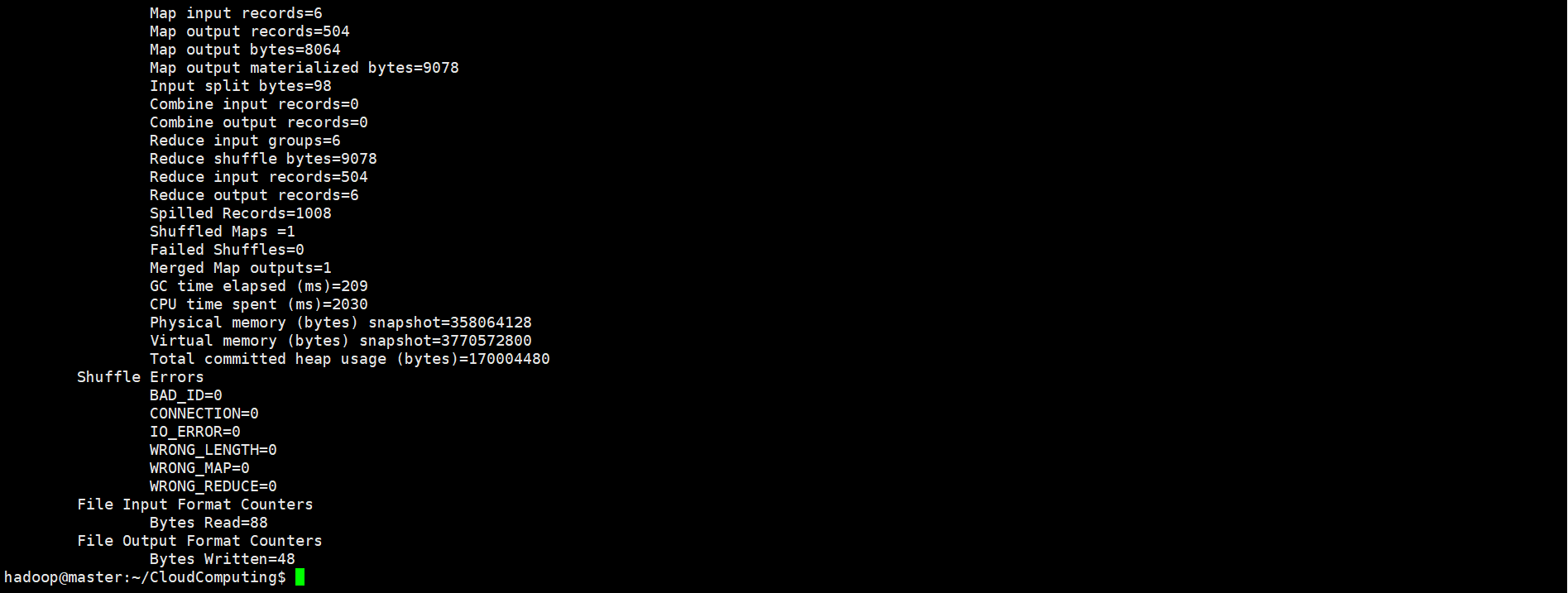
成功运行MapReduce任务KNN之后,使用hdfs dfs -cat /knn/test/*和命令hdfs dfs -cat /knn/result/*查看测试程序用的测试集数据以及KNN算法的预测分类结果:
5 总结
项目设计并实现了一个基于MapReduce框架的KNN算法,并在hadoop系统上进行了测试。KNN算法的特点是处理逻辑比较简单,而数据量会比较大,适于用MapReduce框架处理。通过在VMware Workstation Pro上安装的三个虚拟机系统,本项目模拟实践了在集群上进行分布式计算。通过本项目,对云计算的理解有所加深,掌握了基本的云计算的实践方法。
参考:
数据算法:Hadoop/Spark大数据处理技巧 (美)马哈默德·帕瑞斯安(Mahmoud Parsian)著; 苏金国等译. 中国电力出版社,2016.10(北京)