Huggingface:Build, train and deploy state of the art models powered by the reference open source in machine learning.
基础
>
Trainer封装了什么
梯度累计的实现
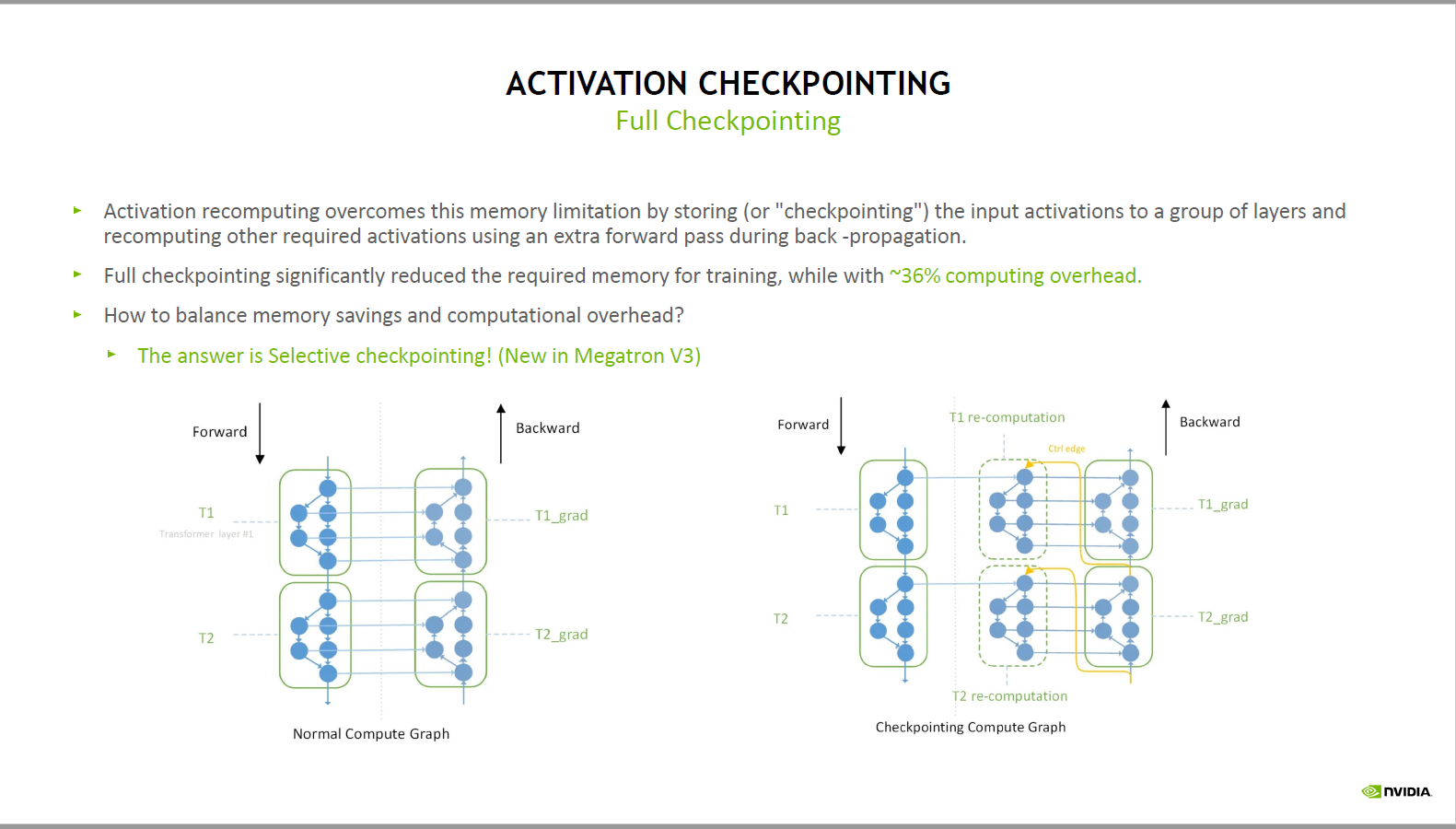
gradient_checkpoint的实现
LoRA的实现/PEFT的实现 https://mp.weixin.qq.com/s/x2mQBE0pfTv8w3Czp8JkDg
grandient checkpoint
- transformers : model.enable_gradient_checkpoint()
- 神经网络的前向传播过程需要保存层与层之间的中间状态参数immediate result,用于反向传播时梯度的计算
- 前向传播:$ y = f(x) $
- 反向传播:$ x^{‘} = y^{‘} f^{‘}(x) $
部分计算量小,但中间状态参数大的神经网络层,在前向传播时将其中间状态参数释放
- 反向传播需要时重新由前向计算得到这一部分中间状态参数
###