(并行与分布式计算四)
连通分量
顶点之间的连通性:在无向图G中,若从顶点$v_i$到顶点$v_j$有路径(当然从$v_j$到$v_i$也一定有路径),则称$v_i$和$v_j$是连通的(Connected)
连通图:若V(G)中任意两个不同的顶点$v_i$和$v_j$都连通(即有路径),则称G为连通图(Connected Graph)
连通分量:无向图G的极大连通子图称为G的连通分量(Connected Component)
寻找连通分量的串行算法
- 深度优先搜索
1.令k=1
2.当图中有顶点未被标记时:
- 任取一个未被标记的顶点v
- 深度优先标记(v, k):把v标记为第k个连通分量中的顶点
- 遍历v的未被标记的相邻顶点u: 递归地深度优先标记(u,k)
3.令k=k+1
- 广度优先搜索
1.令k=1
2.当图中有顶点未被标记时:
- 任取一个未被标记的顶点v
- 把v标记为第k个连通分量中的顶点
- 用v的相邻顶点组成集合U
- 当U非空时:
把U中的顶点v都标记为第k个连通分量中的顶点;
更新U,用旧的U中的顶点的未被标记的相邻顶点组成新的U
3.令k=k+1
算法可并行化程度分析
深度优先搜索算法:
- 外循环用到连通分量编号k,不可并行
- 内循环用到前一个访问的顶点的标记,不可并行
广度优先搜索算法:
- 外循环用到连通分量编号k,不可并行
- 内循环只用到上一次内循环的标记,可以并行
广度优先搜索的并行性更好
改进寻找连通分量的算法的并行性
- 广度优先搜索算法
- 外循环的不可并行性问题是否可以解决
问题在于连通分量的编号方式:
- 连通分量的连续整数编号
- 需要依次搜索各个连通分量来保证:连通分量内编号相同,连通分量外编号不同
采用其它方式来为连通分量编号:
- 同一连通分量内的深度和广度优先探索都形成搜索树
- 用树根顶点作为连通分量的编号
- 不需要依次搜索各个连通分量
全并行连通分量搜索算法
基本思想:
- 相邻的顶点可以合并为超顶点
- 相邻的超顶点可以继续合并为更大的超顶点
- 继续合并,直到把同一连通分量中的顶点都合并为一个超顶点
- 最终的结果是一个连通分量一个超顶点,用超顶点内编号最小的顶点来标记这个超顶点即可
顶点合并技巧: 合并方向函数
- 编号是极小值点的顶点或超顶点合并其它顶点或超顶点
- 定义合并方向函数$C(u) = min{v: v是u的邻居}$
- 上述合并方向函数C(u)形成伪森林,同一伪树包含在同一个连通分量里,但是同一连通分量里可能有多个伪树
伪树:
A pseudoforest is a directed graph in which each vertex has an outdegree less than or equal to 1.
顶点合并技巧:伪树的星化
- 每棵伪树内都只有一个环
- 根是环内编号更小的节点
- 如果用指针跳转法来跳转,当跳转步数大于或等于伪树的高度时,伪树上的所有节点都跳到环内的两个顶点之一
- 如果在使用指针跳转法之前先把伪树的环修改为从根指向根(loop)的回路,则当跳转步数大于或等于伪树的高度时,伪树上的所有节点都跳到伪树的根上
星化伪树: A rooted star is a directed tree that each vertex is directly connected to the root r.
顶点合并技巧:星化伪树的超顶点合并
- 星化的伪树合并为以根为标记的超顶点
- 当且仅当两个超顶点中的顶点有跨越超顶点的边连接时,这两个超顶点是相邻的
- 超顶点使用前面同样的合并方向函数来构造更高级别的伪树
- 更高级别的伪树又可以用同样的指针跳转法来星化,从而合并成更高级别的超顶点
- 继续合并,直到每个连通分量只剩一个超顶点
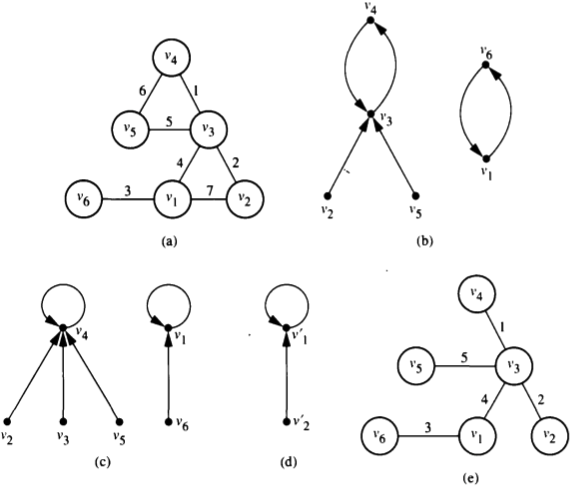
无向图G=(V, E),定义函数C: C(v)=min{u | A(u, v) = 1}(A为图G邻接矩阵),C(v)=v当且仅当v是孤立点;
C定义了一棵伪树;
树根定义为伪树中编号最小顶点
用指针跳转法(pointer jumping)将每个伪树收缩为超顶点(supervertex),每个超顶点都孤立时算法停止
如果超顶点$r_i$和$r_j$邻接(存在连接两个顶点集的两个顶点的边),则插入边($r_i$, $r_j$); 继续进行收缩
Algorithm 5.1
|
|
- A是邻接矩阵,D是每个顶点所在的连通分量中标号最小的顶点
- $T = O(log^2n)$, $W = O(n^2)$
- W的主要部分是计算超顶点之间的边
该算法并行复杂度的最优性分析
- 串行算法的复杂度是O(m+n),其中m是边数, n是顶点数
- 如果$m=O(n^2)$,那么前述并行算法就是最优的
- 当图是稠密的时候,$m=O(n^2)$
- 然而,也有很多图是稀疏的
针对稀疏图改进连通分量并行算法
改进$T(O(log^2n) -> O(logn))$:
不用等一个级别内的所有伪树都星化了再做下一级别
嫁接法(Grafting): 伪森林中两棵相异的树$T_i$和$T_j$由D定义,$T_i$的根$r_i$,v是$T_j$一个顶点,将$T_i$嫁接到$T_j$是指D(r_i) = v的操作
- 非对称嫁接:当发现伪树的根大于伪树上某个节点的邻居的(不在原伪树上的)父结点时,把该根连接到该父结点上
if D(u) = D(D(u)) and D(v) = D(D(v)), which will result in an attempt to graft $T_i$ onto $T_j$ and $T_j$ onto $T_i$ simultaneously. To avoid such a difficulty we insist on grafting a tree onto a smaller vertex of another tree:
Given an edge (u, v) belongs to E, we check whether D(u) = D(D(u)) and D(v) = D(D(u)) and D(v) < D(u), and, if they are, we graft $T_i$ onto $T_j$, that is we set D(D(u) = D(v))
- 星嫁接:(在非对称嫁接完成之后)如果一颗伪树已星化且非对称嫁接失败(伪树的根小于所有伪树上的节点的邻居的父结点),就检查伪树上的节点有没有邻居不在伪树上,如果有则任选一个不在伪树上的邻居,把伪树根连接到该邻居的当前父结点
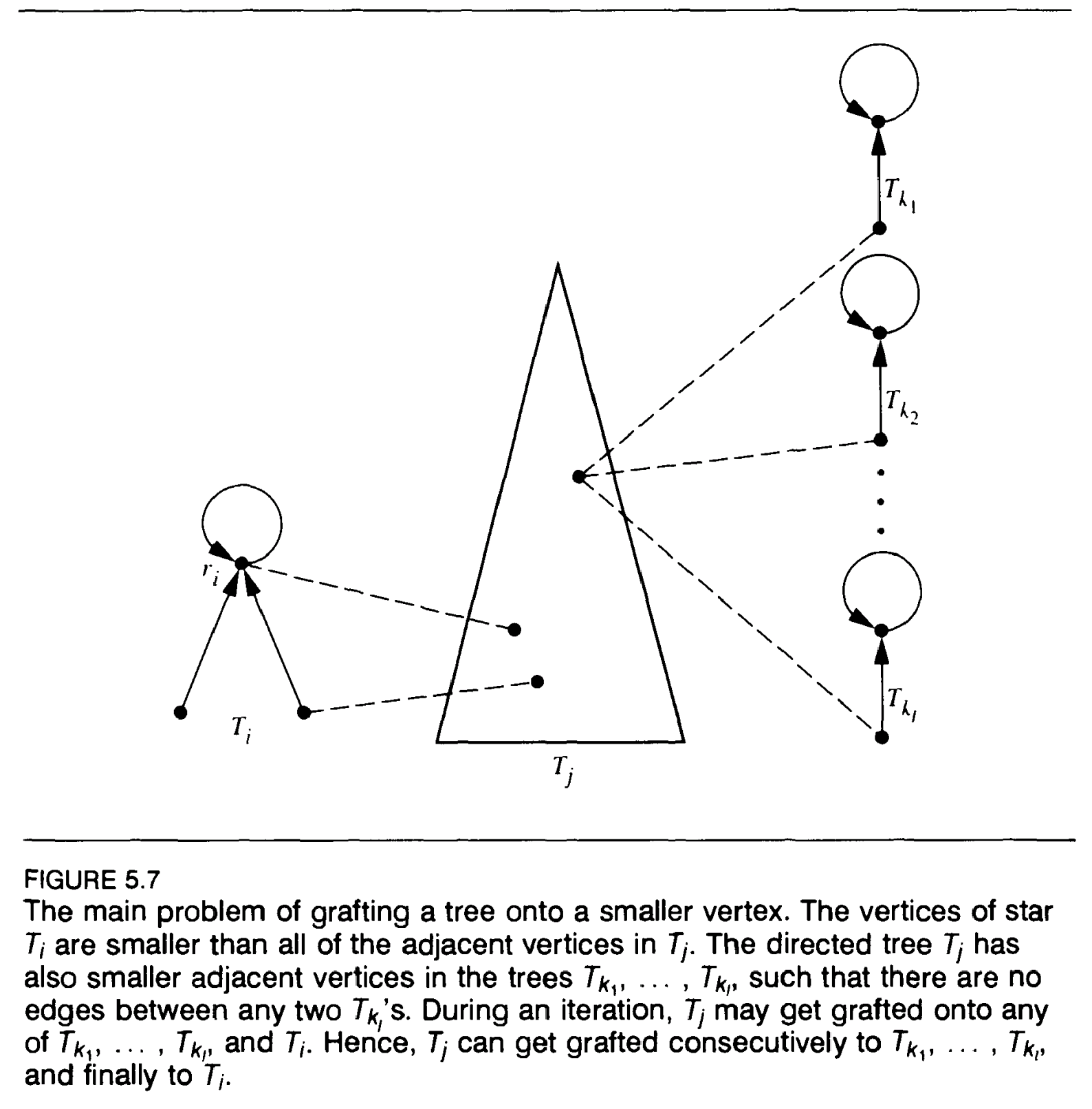

嫁接后续工作:继续用指针跳转法星化伪树(连通分量内的伪树之高总和不会因为嫁接变大,并且,每个指针跳转迭代都至少乘以2/3)
改进$W(O(n^2) -> O((m + n)logn))$:
Algorithm 5.2
- 非对称嫁接不会使连通分量里的伪树的高度总和变大
- 星嫁接不会使连通分量里的伪树的高度总和变大
- (一遍)指针跳转法压缩伪树把不是星化伪树的高度降为至少原来的2/3
(高度为1的不再降、高度为2的降为1、高度为3的降为2、高度为4的将为2……)
最小生成树
在一给定的无向图 G = (V, E) 中,(u, v) 代表连接顶点 u 与顶点 v 的边,而 w(u, v) 代表此边的权重
若存在 T 为 E 的子集且为无循环图,使得 的 w(T) 最小,则此 T 为 G 的最小生成树
最小生成树其实是最小权重生成树的简称
最小生成树串行算法
输入:一个加权连通图,其中顶点集合为V,边集合为E
初始化:$V{new} = {x}$,其中x为集合V中的任一节点(起始点),$E{new}= {}$,为空
重复下列操作,直到$V_{new} = V$:
在集合E中选取权值最小的边
将v加入集合$V{new}$中,将
输出:使用集合$V{new}$和$E{new}$来描述所得到的最小生成树
Prim’s algorithm
kruskal’s algorithm
最小生成树并行算法
基本思想:
如果(u,C(u))是从u出发的最小权边,则(u,C(u))必在最小生成树中;
若不然,设最小生成树中从u到C(u)的路径是u,x_1,x_2,…,x_s,C(u),则另一路径u,C(u),x_s,…,x_2,x_1串连了这些节点,并且权和更小函数C定义了一个伪森林,使得其中的每棵伪树上有且仅有一个环
用指针跳转法可以把每棵伪树星化,并聚合成超顶点
取超顶点之间的边权为它们的跨伪树的连接边的最小权,并用C(.)来生成另一级别的伪森林,从而可以继续星化和合并超顶点
- Sollin’s MST algorithm
- $T = O(log^2n), W = O(n^2)$
Algorithm 5.3